
ChatGPT’s ability to converse is something we’ve all experienced, whether it’s in its text generation abilities, coding skills, or contextualized conversation capabilities – each time leaving us in awe.
Do you remember the GPT4 press conference where they showcased its multimodal ability? Input could not only be text, but also text and images.
For example, input: (see image) what happens when a glove falls off?
Output: it falls onto the wooden board and the ball is launched.

Furthermore, by simply sketching out a website, GPT4 can immediately generate HTML code for the site.
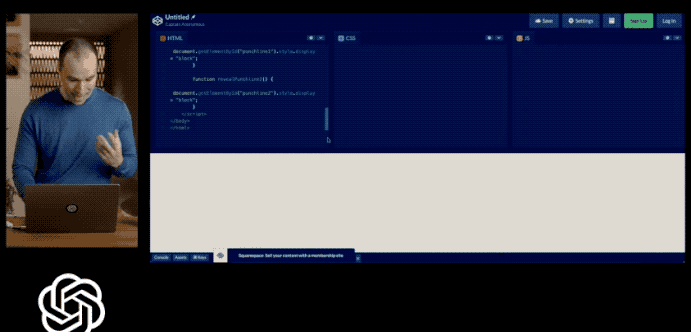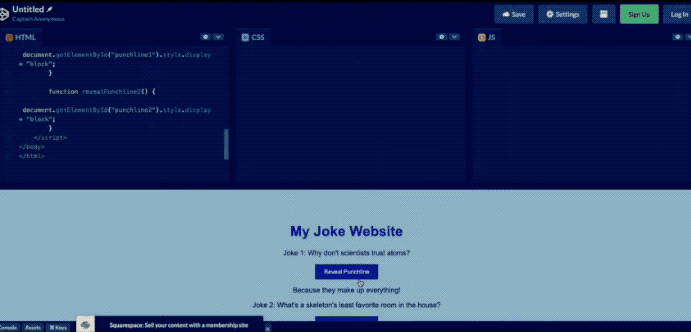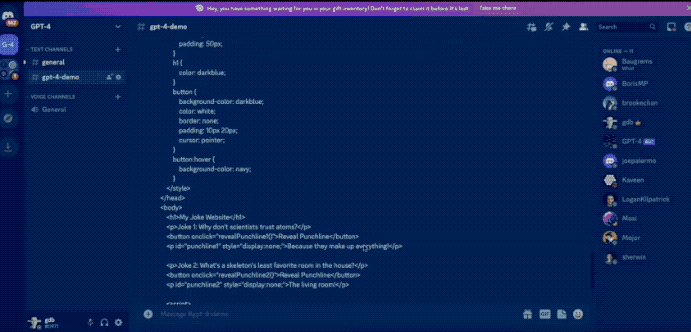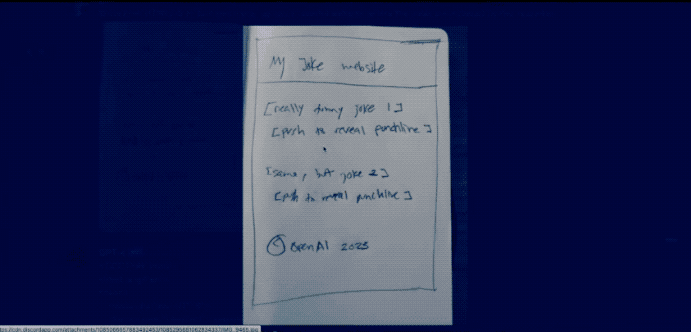
However, over a month has passed since the conference, and OpenAI has yet to provide the showcased multimodal processing capabilities.
Initially, many thought an official update was necessary to experience this new feature, but to everyone’s surprise, a project called MiniGPT-4 arose.
MiniGPT-4 is an open-source project developed by several doctoral students at King Abdulaziz University of Science and Technology.
Most importantly, it’s completely open source and the end result is demonstrated in this video:
As we can see, MiniGPT-4 can support both text and image input, achieving multimodal input.
GitHub: https://github.com/Vision-CAIR/MiniGPT-4
Online demo: https://minigpt-4.github.io
The author also provides a web demo for anyone to try:
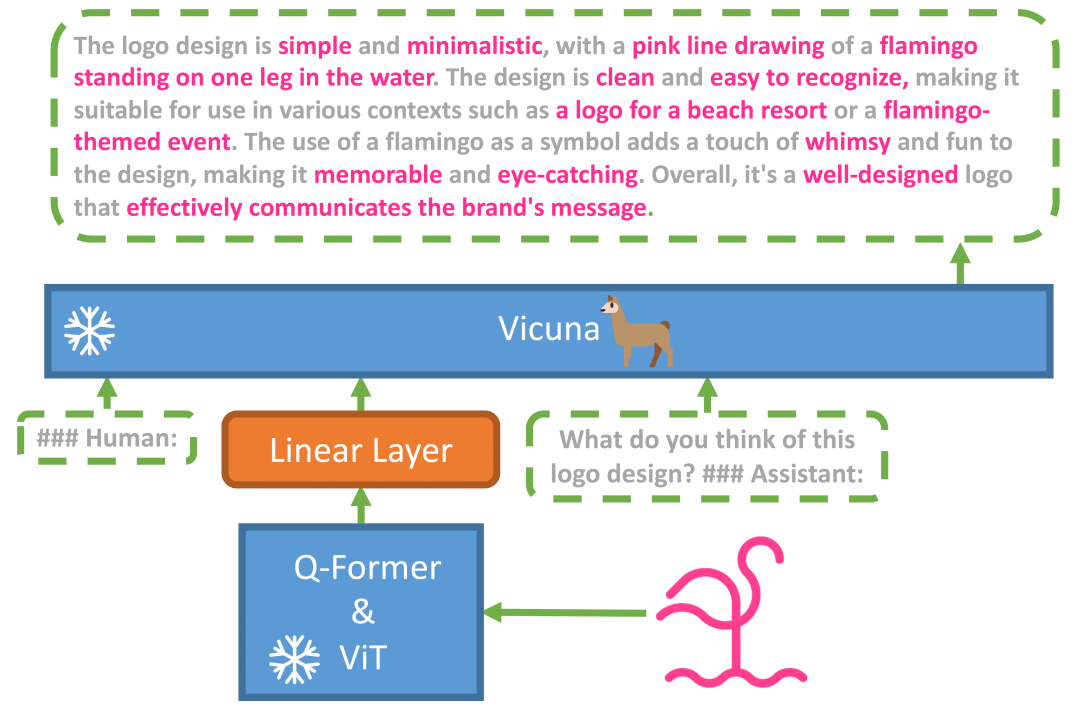
MiniGPT-4 was trained on a few large open-source models, which were fine-tuned in two phases: first, by training on 5 million image-text pairs on 4 A100s, then fine-tuning on small high-quality datasets. Training on a single A100 only takes 7 minutes.
However, there are currently many users using this service, so it’s best to use off-peak hours or deploy a local service.
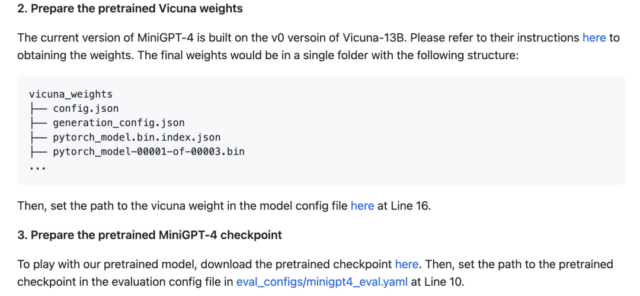
The local deployment process is not complicated – just follow the official tutorial to configure the environment:
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4
Then download the pre-trained model:
Finally, run the command:
python demo.py –cfg-path eval_configs/minigpt4_eval.yaml
During this process, ensure that you have a network connection and the necessary dependencies downloaded, such as BLIP.
Soon, it’s likely not only to be multimodal input, but also multimodal output.
We’ll be able to input text, images, audio, and video, and AI will generate the required text, images, audio, or even videos based on our needs.